
Kontakt
- Let’s connect!
- +49 (0)931 780998-87
- hello@ososoft.de
- Kontaktformular


14.02.2023 | Khang Nguyen
Die SAP BTP "Document Information Extraction" ist ein Funktionsbereich in SAP Business Technology Platform (BTP), der es ermöglicht, unstrukturierte Dokumente wie beispielsweise PDF- oder Word-Dateien automatisch zu analysieren und Informationen daraus zu extrahieren. Dies kann beispielsweise dazu verwendet werden, Daten aus Rechnungen, Lieferscheinen oder anderen Geschäftsdokumenten in eine digitale Form zu bringen und für weitere Verarbeitung und Analyse bereitzustellen.
Diese nutzt dabei Technologien wie künstliche Intelligenz und maschinelles Lernen, um die Dokumente automatisch zu lesen und relevante Informationen wie Daten, Namen, Adressen, Preise, etc. zu erkennen und zu extrahieren. Die extrahierten Informationen können dann in einem zentralen Datenlager gespeichert und verwendet werden, um Geschäftsprozesse zu automatisieren und Effizienzgewinne zu erzielen.
Mit SAP BTP können Unternehmen ihre Prozesse effizienter gestalten und Zeit und Kosten sparen, indem sie manuelle Dateneingabe und -verarbeitung durch automatisierte Prozesse ersetzen. Mit „Document Information Extraction“ kann man:
Informationsextraktion
Automatisierte Erfassung relevanter Daten aus geschäftsrelevanten Dokumenten. Die Dokumenten-API akzeptiert Dokumentendateien als Eingabe und gibt die strukturierten Daten von Kopffeldern und Zeilenpositionen aus.
Anreicherung von Daten
Verwenden Sie die aus einem Geschäftsdokument gewonnenen Daten, um den Datensatz mit einer Datenquelle für die Anreicherung abzugleichen. Bei der Eingabe von Dokumentendateien liefert die Anreicherungsdaten-API die ID der abgeglichenen Anreicherungsdatensätze.
5. Nach der erfolgreichen Durchführung sollte dieses Fenster erscheinen
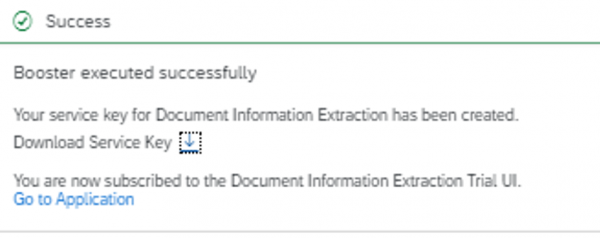
6. Anschließend müssen Sie auf „Go to Application“ klicken, dann haben Sie erfolgreich einen Booster benutzt, um den Service einzurichten.
1. Um ein neues Dokument hochzuladen, klicken sie oben rechts auf das Plus-Symbol

2. Anschließend erscheint eine 2. Seite von rechts, auf dieser können Sie entweder per Drag and Drop das Dokument reinziehen oder auf das blaue Plus-Symbol klicken, um ein Dokument hochzuladen
3. Nun müssen Sie die Art des Dokumentes auswählen und mit dem „Step 2“-Button bestätigen
4. Im nächsten Schritt wählen sie die gewünschten Daten in der Checkboxliste aus, die ausgelesen werden sollen und bestätigen mit der dem „Step 3“-Button
5. Der nächste Schritt ist optional, hier können noch zusätzlich die Einzelposten Spalte auswählen
6. Nach dem Sie auf den „Review“-Button geklickt haben, erscheint eine Übersicht über die von Ihnen ausgewählten Elementen und damit können Sie alles überprüfen, ob es Ihnen passt.
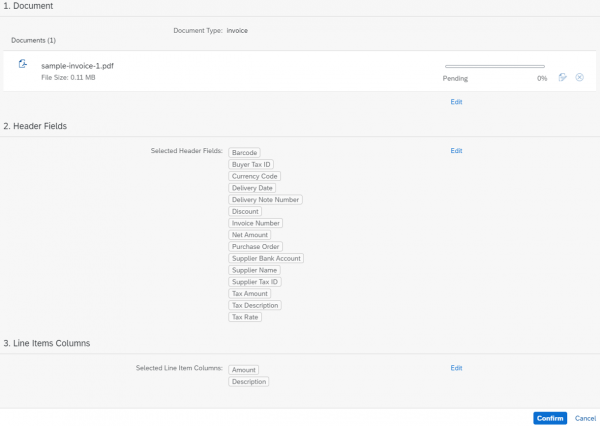
7. Sie können alles überprüfen, ob alles in Ordnung ist und ggf. bearbeiten, mit dem „Confirm“-Button können sie Ihre Auswahl bestätigen
8. Nun erscheint Ihr hochgeladenes Dokument im Startbildschirm des Services, mit dem Status „Pending“
![]()
9. Sobald das Dokument fertig verarbeitet ist, wechselt der Status zu „Ready“ und erst jetzt können Sie draufklicken und das Dokument anzuschauen
10. Um die Ausgelesen Daten anzuschauen zu können, müssen Sie oben rechts auf „Extraction Results“ klicken
11. Die ausgelesen Daten werden mit einer von drei Farben versehen, die beschreibt zu wie viel Prozent die Daten korrekt ausgelesen worden sind. Wenn man über die Daten geht, steht der genaue Wert nochmal da.
12. Sie können fehlerhaft ausgelesene Daten auch bearbeiten und speichern
13. Sobald man alles überprüft ist, gibt es auch die Möglichkeit die ausgelesenen Daten runter zuladen und anderweitig weiterzuverwenden. Mögliche Downloadformate: .csv / .json / .txt

Wir hoffen, Ihnen einen verständlichen Überblick über die SAP BTP Document Information Extraction gegeben zu haben. Falls Sie nun noch mehr Fragen zum Thema haben, schauen Sie in unsere weiteren Beiträge zum Thema oder kontaktieren Sie uns - Unsere Berater und Entwickler helfen Ihnen immer gerne weiter!